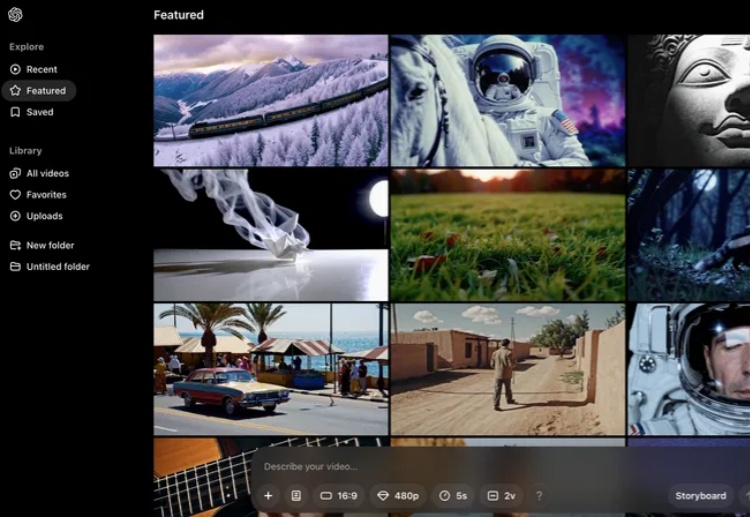
Sora发布!这次的惊艳居然不在模型,而是产品设计和制作流
Sora发布!这次的惊艳居然不在模型,而是产品设计和制作流OpenAI发布会直播第3天,继第1天完全版o1和200美元月费ChatGPT Pro会员,以及第2天的强化微调工具后,OpenAI终于填上9个月前的期货大坑,正式发布了观众敲碗已久的全新视频生成模型——Sora Turbo。
来自主题: AI资讯
8210 点击 2024-12-10 11:53
 搜索
搜索
OpenAI发布会直播第3天,继第1天完全版o1和200美元月费ChatGPT Pro会员,以及第2天的强化微调工具后,OpenAI终于填上9个月前的期货大坑,正式发布了观众敲碗已久的全新视频生成模型——Sora Turbo。

在伦敦举行的C21Media主题演讲中,OpenAI的Chad Nelson展示了即将推出的Sora v2。Sora v2提供的功能:根据演讲透露,Sora v2将“非常非常快”上线,这是现场泄露出来的一段视频

艺术家「反水」? Sora 就这么水灵灵地用上了。 今天凌晨,OpenAI 视频生成工具 Sora 的内测版本遭到泄露,起因是部分早期测试人员(艺术家)对 OpenAI 产生了不满。
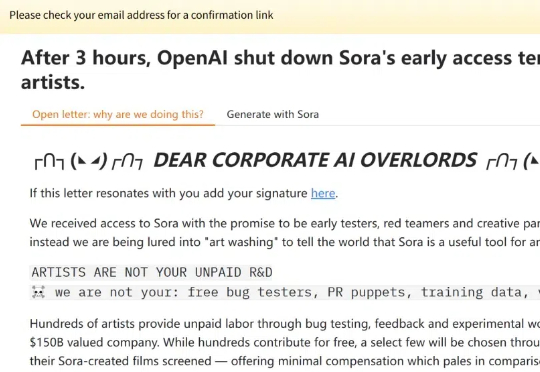
一觉醒来,挺突然的,Sora API 就这么泄露了。

Sora 的发布让广大研究者及开发者深刻认识到基于 Transformer 架构扩散模型的巨大潜力。作为这一类的代表性工作,DiT 模型抛弃了传统的 U-Net 扩散架构,转而使用直筒型去噪模型。鉴于直筒型 DiT 在隐空间生成任务上效果出众,后续的一些工作如 PixArt、SD3 等等也都不约而同地使用了直筒型架构。
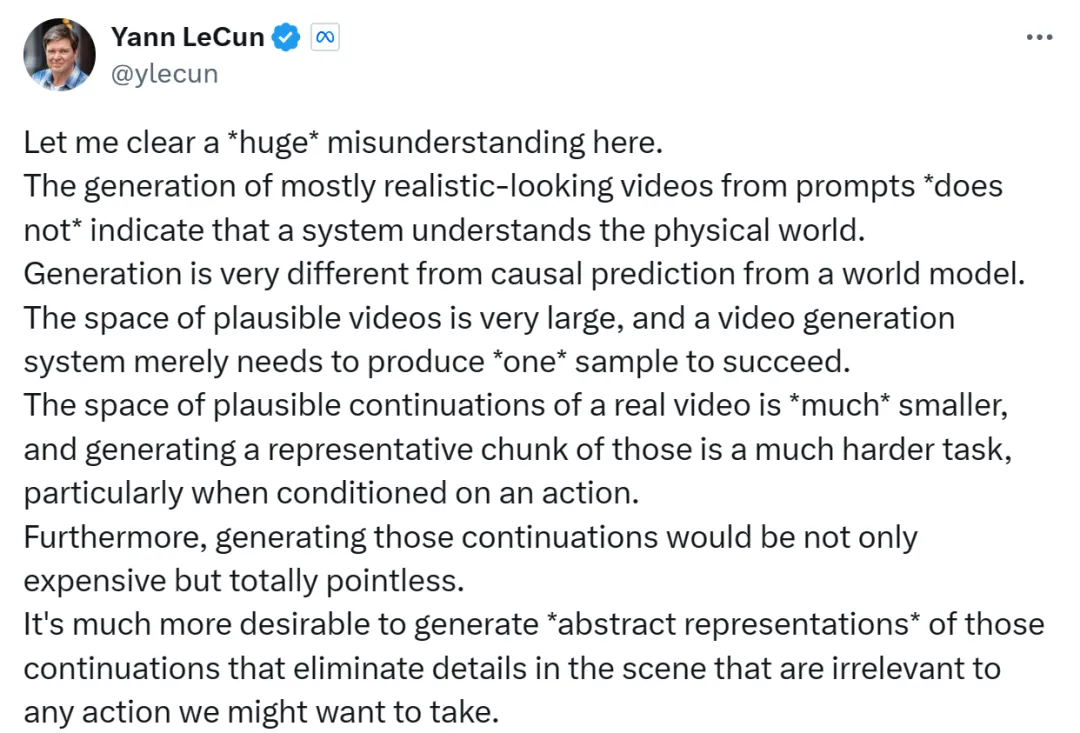
自从 Sora 横空出世,业界便掀起了一场「视频生成模型到底懂不懂物理规律」的争论。图灵奖得主 Yann LeCun 明确表示,基于文本提示生成的逼真视频并不代表模型真正理解了物理世界。之后更是直言,像 Sora 这样通过生成像素来建模世界的方式注定要失败。

10 月 31 日,以色列 AI 游戏视频生成公司 Decart 宣布获得红杉美国领投的 2100 万美元种子轮融资。

腾讯 AI Lab 联合中科大发布了一份针对类 SORA 视频生成模型的测评报告,重点聚焦目前最前沿的类 SORA DiT 架构的高质量视频生成闭源模型
面对以 Sora 为代表的各种「后辈」视频生成模型的冲击,Pika 迟迟没有大的版本更新。

9月 24 日,字节跳动的豆包大模型发布多款新品——视频生成、音乐生成以及同声传译大模型。